
In experiments mimicking real-world judicial decision making with real judges, we randomly vary the formal legal authorities (precedents, statutes, etc.). We find at best modest effects of these authorities on ultimate decisions, even while participating judges discuss these authorities in the reasons they give for these decisions.
What factors drive judicial decisions? The determinants of judicial decisions are of obvious interest, not only to attorneys but to a wider public. In recent years, for instance, there has been much discussion of judicial bias in areas such as criminal sentencing. But the question of what drives judicial decision making goes much deeper. A century ago, the legal realists made an extensive argument that the formal legal authorities—statutes and precedents—are not the real drivers of judicial decisions. Today, all serious legal theory acknowledges at least some role for extra-legal factors. “Extra-legal” does not necessarily mean bias. Normative theories for filling the gaps among legal authorities—and construing them in the first place—inject a contestable element into judging. So do policy-relevant beliefs about the likely effects of various decisions. But the influence of such theories and beliefs is not illegitimate. It is unavoidable.
What features influence judging and how—is an engineering question, or at least it could be.
Still, the question remains about the balance of these various determinants. For litigators, the question is where to focus their argumentative efforts: formal legal argument, policy implications (not to say politics), or emotions? Or is it all about maneuvering to get a favorable decision-maker (judge, arbitrator) in the first place? Does it matter where one is litigating—is it pointless to argue precedent to a civil law judge? For policy-makers and the public at large, the question is how much they can expect of judges and, by extension, the rule of law? More constructively, the question is what features of judicial selection, procedure, and legal authorities affect the balance, and how?
This last question—what features influence judging and how—is an engineering question, or at least it could be. Alas, the law is notoriously hostile to innovation and experimentation that would be considered essential in other areas like industrial processes or medicine. At best, we get “pilot projects,” but proper randomized trials and purposeful experiments are few and far between. This has forced researchers to rely on what is known as observational data; for example, data that is generated in the normal course of operations. The problem with observational data—as opposed to experiments—is that it tends to be confounded by a variety of influences beyond the one of interest.
Take politics and disagreement on the U.S. Supreme Court. The nine justices routinely divide along partisan lines in politically salient cases. But do they do so because of rote political allegiances (illegitimate) or because of judicial philosophies (legitimate, even though politicians may have nominated them for holding these—to politicians—congenial philosophies)? Relatedly, do these splits in hard cases betray a general indeterminacy of the law, or is it something specific to hard cases? After all, most cases do not generate the level of division that gets a case to the Supreme Court.
Judges are highly trained, highly selected, and subject to strong professional norms that other populations cannot well approximate.
We have at least a partial answer to the last question: no, deep, persistent judicial divisions are not limited to the hard cases that reach the Supreme Court. In asylum cases, some immigration judges grant asylum to virtually nobody, while others grant it to almost everyone—even when applicants are randomly assigned to judges (such that the cases are statistically indistinguishable). Similar discrepancies among individual judges in statistically indistinguishable cases have long been documented in many areas.
At the other extreme, it’s easy to think of examples where the law is followed near perfectly. From the day the U.S. Supreme Court handed down Obergefell, same-sex marriages were being registered and recognized virtually without exception throughout the United States. Similarly, it is hard to argue that mandatory minimums or the sentencing guidelines make no difference in criminal sentencing. But the question is: How much of a difference? Which authorities are determinative, and which aren’t? Which are more common?
In a series of experiments, several co-authors and I set out to answer some of these questions. A preliminary question is how one could possibly hope to do so. Could one use law students as experimental subjects to study judicial behavior, much like standard psychology experiments use college students to study human behavior in general? We rejected this idea because judges are highly trained, highly selected, and subject to strong professional norms that other populations cannot well approximate. (We have since validated this concern experimentally—law students decide nothing like actual judges. In particular, students do follow precedent. They also approach legal materials differently.)
The first experiment
With the help of the Federal Justice Center (FJC) and similar organizations in other countries, we recruited 361 judges from seven countries for two rounds of experiments. In both cases, we asked the judge-participants to decide a legal case. The case was briefed, we provided all relevant legal materials, and the judges had about an hour to reach a decision—more time than they have for many motions that they need to decide in the real world. Our goal was to get as close to real-world decision making as we possibly could.
For our first experiment, we chose a war crimes case before the International Criminal Court for the former Yugoslavia (ICTY) to make it accessible for judges from different jurisdictions (discussed below). In the second experiment, administered only to U.S. judges, we followed up with a U.S. domestic case, with similar results.
Our first experiment’s case is a defendant’s appeal of his conviction by the ICTY’s trial chamber for aiding and abetting war crimes in the Bosnian civil war. We asked our participants to imagine they were sitting on the ICTY’s appeal chamber and had to decide the defendant’s appeal. The defendant had been the chief of the army of one of the neighboring countries, Croatia or Serbia, in charge of organizing support for its ethnic brethren in Bosnia. The supported militia committed war crimes. The defendant knew this. The question was whether this was sufficient for a conviction for aiding and abetting under Article 7(1) of the ICTY statute, or whether such conviction required that the aid be “specifically directed” at the war crime—a question that divided the ICTY and commentators for a while. We did not tell participants about this controversy per se. Instead, we presented the case as if only one of two horizontal precedents—a prior decision by the same appeals chamber that the participants were asked to imagine sitting on—existed: one requiring “specific direction” obiter dicta, and one arguing at length against such a requirement, albeit on distinguishable facts. Each participant was randomly assigned one of these two precedents. We wrote separate briefs around the respective single precedent. The briefs and a statement of facts were short so that participants could realistically decide the case in one hour (which almost all of them managed with time to spare). All the other materials (trial court judgment, precedent, statute) were real.
Going into the experiment, we expected that the precedent would have a strong effect—what else did the judges have to go by?
Another aspect of the case that we varied experimentally, and randomly assigned to participants, was the nationality and certain legally irrelevant attributes of the defendant. In short, one was a remorseful, conciliatory Croat, whereas the other was a hateful, nationalist Serb (both fictitious, and we mean to imply no judgment about Croats and Serbs, even though we did mean to play on what we believe to be stereotypical images of Croats and Serbs in the conflict, especially in the United States). These defendant differences might be legally relevant at sentencing but not in the guilt phase of the proceedings, which was the setting of our experiment. All materials were adjusted to fit the respective defendant, down to the names and places in the trial judgments. The irrelevant attributes were inserted inconspicuously in the briefs and trial judgment.
As stated above, our goal had been to assess the respective strengths of these two factors: precedent and defendant sympathy. Going into the experiment, we expected that the precedent would have a strong effect—what else did the judges have to go by? We were less sure about the defendant—after all, there is only so much one can convey about a defendant in words without arousing participants’ suspicions, and it would seem easier to disregard concerns for a fictitious individual in a paper (well, iPad) exercise than for a flesh-and-blood human being in the courtroom. Just to be sure, we surveyed colleagues at a number of law schools in the United States. Their predictions matched ours.
We first ran the experiment with 32 U.S. federal judges (circuit, district, bankruptcy, and magistrate). The results were the opposite of what we and other law professors expected. The precedent had no effect whatsoever. By contrast, the conviction of the unsympathetic Serb defendant was confirmed at a much higher rate (87%) than that of the sympathetic Croat (41%). Even in our comparatively small sample, such a difference would arise by random chance with less than 1 percent probability.
Across all judges combined, precedent effect is barely detectable.
Shocked by this result, we upped the ante in subsequent rounds of our first experiment, which we conducted with judges in Argentina, Brazil, China, France, Germany, and India. We added a third precedent to the set of precedents randomized to individual participants. This precedent was the strongest horizontal precedent imaginable: the actual appellate decision by the ICTY appeals chamber in the case presented to our participants. Of course, we disguised this decision by changing the names of people and places and some elements of the defendant’s biography to make it look like a different case. But all the relevant facts were the same. If ever there was a precedent that could not be distinguished, this was it. And yet, judges largely ignored it. This was not because five of the six jurisdictions belong to the civil law. The only judges who may have been moved by precedent were those from Brazil, China, and perhaps Germany—all civil law jurisdictions. (We say “may” because of the possibility of sampling error.) By contrast, the precedent did not make a dent with judges in India, the only other common-law jurisdiction in our sample. Across all judges combined, precedent effect is barely detectable. Even taking into account sampling error, any precedent effect is very unlikely to be much larger than the effect of our defendant manipulation, which clearly should have no effect whatsoever but appeared to have one in our sample.
Intermission: Common vs. civil law?
Let us pause here briefly to discuss the common/civil law distinction. Our data clearly does not support the old canard that common lawyers heed precedent whereas civil lawyers do not. And there is more. While our judge-participants worked on the case, we tracked their document use (see figure 1). We can compare if common and civil lawyers took different “paths” through the case. For example, did common lawyers tend to start with the precedent and then take only a brief look at the statute, whereas civil lawyers tended to do the reverse? Did one of the two groups engage more deeply with the trial judgment as evidenced by, for example, frequently looking back at it? We examined this question using a technique borrowed from disciplines such as genome comparisons. We found no evidence for differences between common and civil law (as opposed to differences between individual countries, which are marked). Similarly, we found no common/civil law differences in judges’ mention of precedent, statute, or policy in their written reasons (versus differences between individual countries). In brief, we found no evidence for the common assertion that common and civil lawyers “think differently” (see figure 2).
Graphing the results
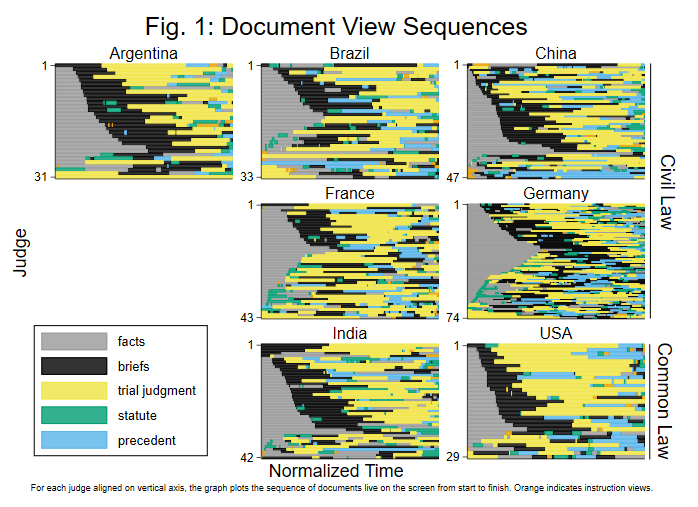
This figure shows document view paths by country. Each of the seven panels represents judges from one country—the first five from the civil law, the last two from the common law. Within each panel, judges’ view paths run left to right, and individual judges are stacked vertically. The different colors indicate the different documents that were live on any particular judge’s screen at that time; the colors are explained in the bottom legend. Overall view time is normalized such that each judge’s path is of equal length, i.e., the length of any judge’s path segments is relative to the overall time spent by that judge. One can discern differences between countries but no pattern between the common and civil law groups.
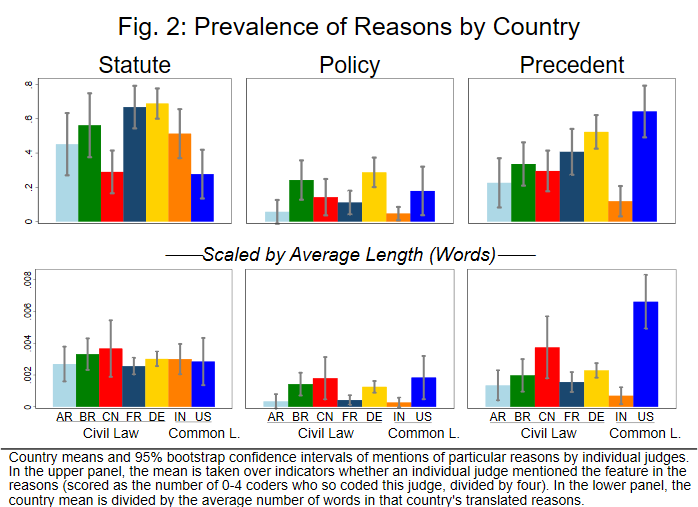
This figure shows country-prevalence of key arguments (statute, policy, and precedent) in the written reasons. The upper panel presents the raw country-prevalence of each argument, i.e., the fraction of judges from that country that mentioned the argument in their reasons. The lower panel divides the country-prevalence by the average number of words written by judges from the respective country. There are no common/civil law differences; the biggest country differences are between the two common law countries India and USA.
The second experiment
Let us return to the United States, specifically to U.S. federal judges, and more specifically to our second experiment. One concern with our first experiment was that an international criminal case is artificial on two dimensions: U.S. federal judges don’t decide ICTY cases in real life, and even ICTY judges don’t do so in an hour. Another concern was that war crimes elicit extreme emotional responses. What if we took a domestic case, one that U.S. federal judges might actually decide in real life, and perhaps a run-of-the-mill civil case to tame the emotions? That’s what I did with a different co-author in a second experiment. We again recruited federal judges (61 of them) with the help of the FJC, provided briefs and full legal materials, and gave them an hour to decide the case. But this time, the case was a simple tort damages claim arising from a traffic accident, more specifically asking the question of which state’s damages law applied to the case: Kansas’s, which caps noneconomic damages at $250,000, or Nebraska’s, which does not. We told participants to imagine that they took over the case after trial from another federal district judge. The initial judge had already drafted “Findings of Fact and Conclusions of Law” and asked the parties for supplemental post-trial briefings on the question of the applicable law. Then the judge had had a stroke. Participants took over at this stage—as they might in real life.
We found no evidence for the common assertion that common and civil lawyers “think differently.”
We again experimentally (randomly) varied two aspects of the case: who was the sympathetic party (plaintiff or defendant), and who had the law in their favor. We varied the personal appeal of the parties by various small details interspersed in the facts, the worst of which was the unsympathetic party’s use of a racial slur (which had an indirect role in precipitating the accident and hence was hopefully inconspicuous). We varied the demands of the law by varying forum and accident location. The case was litigated either in Wyoming, which follows the traditional lex loci delicti rule, or in South Dakota, which follows the Restatement (Second) of Conflict of Laws standard. Under lex loci delicti, the law applicable to damages is the law of the place where the accident happened. Under the Restatement (Second), the law applicable to tort damages in driver-passenger traffic accident is the law of common domicile. In our experimental facts, the accident happened either in Nebraska while the parties resided in Kansas, or the other way around. We varied both forum and accident location because we wanted to test not only whether the law mattered (either would have been enough for that) but whether it mattered more under Wyoming’s rule or South Dakota’s standard. We thought we’d find at least the former. Indeed, we thought Wyoming’s rule, which seems as clear as can be, would fully determine participants’ decisions.
Once again, we were overly optimistic/legalistic. Judges’ decisions did tend to line up with Wyoming’s rule, but not enough that we could confidently rule out that this alignment was due to random chance. (Admittedly, we had a very small sample “in Wyoming” because we undersampled what we thought was a clear and shut case.) More important, judges assigned to the South Dakota forum were equally likely to choose Kansas law no matter where the accident happened—that is, the judges seemed entirely unmoved by South Dakota’s choice of law standard. To be sure, a standard is called a standard for a reason: it is meant to be defeasible in view of a case’s special circumstances. But our case presented no special circumstances. The judges seemed to simply ignore the applicable choice of law principle. A redeeming virtue was that they also seemed to simply ignore who was the sympathetic party, unlike in our first experiment.
What do the experiments tell us about the real world?
One way to make sense of these surprising findings is to explain them away as artefacts of our experimental setting. We do not think this is plausible. It is true that our participants remained anonymous and were not subject to appeal, whereas a defining feature of judging in the real world is publicity and, for all but apex judges, the possibility of review by a higher court. But the vast majority of judicial decisions are not appealed, and many cannot be appealed. Similarly, nothing in participating judges’ behavior or written reasons suggests that they took the experiment’s anonymity as license to free themselves of their usual legalistic constraints. Their written reasons—published alongside our experiment results—are serious and conform to the usual legalistic style of judicial opinions. In the experimental room, the judges exhibited the utmost concentration and dedication, and we had to pry some of them from the case when the time was up. In short, participants very much seemed to be in their usual judicial mindset. Inversely, if judges had wanted to “put up a show” for the experimenter, they presumably would have tried to be especially legalistic to preserve the judiciary’s reputation. That’s not what we found.
In many uses of precedent, its meaning is much less clear and hence much more open to deviation (not to say manipulation) by the judge.
This leaves legal nihilism, or a differentiated view of legal materials, in general and precedent in particular. We favor the latter. As mentioned in the beginning, some precedents clearly do have an effect, such as Obergefell. We believe that the difference between the reception of Obergefell and the disregard of precedent in our experiment is twofold. First, and already mentioned, adherence to Obergefell by lower courts and other decision-makers was at least potentially policed by the U.S. Supreme Court, which, not having changed (much) in composition since Obergefell, was unlikely to reverse itself. Second, and perhaps more important, Obergefell was inscribed in an active legal discourse that established a clear meaning for the decision even before it was handed down—there was no doubt about its meaning and import, and any deviation would have been very visible. But in many uses of precedent, its meaning is much less clear and hence much more open to deviation (not to say manipulation) by the judge. For example, Obergefell v. Hodges itself cited over 100 precedents by various courts, some more than 100 years old, none of which was directly on point, and many of them were thus subject to divergent characterizations by the judges and their audience. This is also typical when lower courts address a novel legal issue. In such cases, our results support the suspicion that precedent has little effect on decisions, whatever its rhetorical appeal.
Next steps
We would love to investigate this question with more experiments. As mentioned before, that would be the natural course of action in any other field, including other fields with very large stakes, particularly medicine. Regrettably, it has not been the attitude of those running the legal system—for example, us lawyers. Perhaps we fear what experiments might reveal. But in a time when the public’s trust in courts is arguably eroding, we may have more to gain than to lose. We can gain both because experimental findings can help us improve the system, and because experimental findings may cleanly document virtues of the judiciary that we presently merely intuit. I, for one, have great respect for the judiciary and was heartened by the seriousness with which our participant judges approached the experimental task. I hope future studies will allow me to resolve the tension between my general impression and the existing experimental and other empirical results.
Holger Spamann is the Lawrence R. Grove Professor of Law at Harvard Law School, where he teaches corporate law and corporate finance. His research focuses on the law and economics of corporate governance and financial markets, judicial behavior, and comparative law.


